European Publication Information Infrastructure - Outline of Implementation
In ENRESSH-VIRTA-POC, the concept of VIRTA technical solution was used to provide a basis for the POC and metadata transfers. This solution included the utilization of CSV-XML converter tool and the use of XML files, that included metadata on research publications, which were then validated at VIRTA's side to control and notify organizations on possible mistakes and missing information in the publication metadata. In the POC, also a concept of Publication Input Service was discussed, but not put into practice. This simple web application would provide a way for organizations to input their publication metadata into the aggregated database without investing in their own system or using some existing registry or CRIS system to provide metadata in bulk.
As an addition to this POC implementation, the previously mentioned two metadata exchange formats is accompanied by the use of OAI-PMH endpoints to make the existing source systems to supply their metadata to aggregated database. As was the case with XML files, the validation of these endpoints is left to European Publication Information Infrastructure and this could be done using the data model and controlled set of mandatory and conditional attributes proposed as part of the deliverables of this STSM.
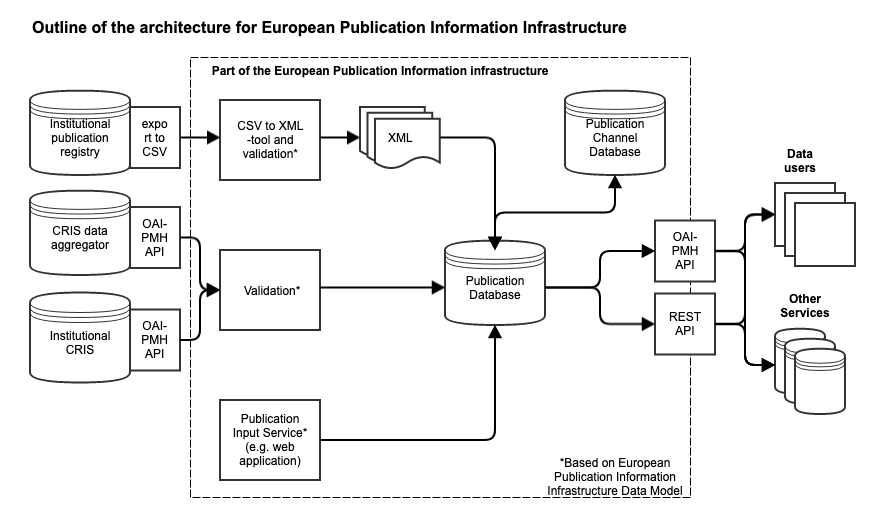
Figure 1: Outline of the architecture for European Publication Information Infrastructure
European Publication Information Infrastructure - a Set of Use Cases
To support the outlining of infrastructure of European Publication Information Infrastructure, a set of use cases should be made to support and demonstrate the possibilities of European wide bibliographic database for the whole of research domain. For the purposes of demonstrating these use cases, only a few use cases are visualized to give a better understanding on how European Publication Information Infrastructure could support various stakeholders in research domain. For future work, the number of use cases should be increased to show off the full potential of this European database.
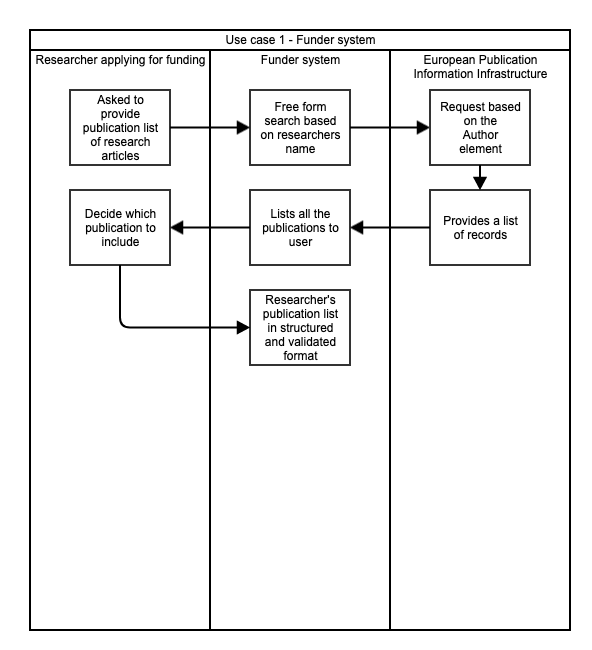
Figure 2: Funder system use case of European Publication Information Infrastructure
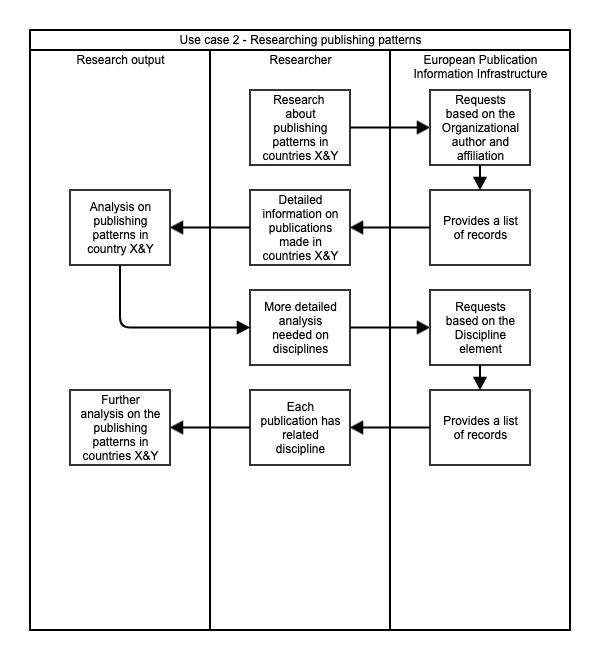
Figure 3: Researcher use case of European Publication Information Infrastructure
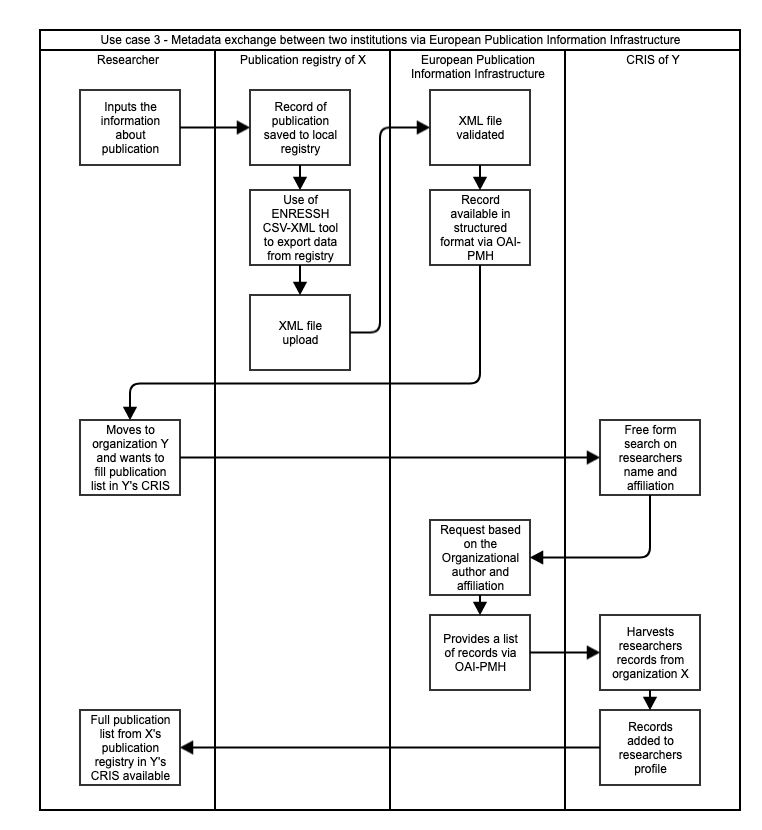
Figure 4: Metadata exchange use case of European Publication Information Infrastructure
European Publication Information Infrastructure in Relation to OpenAIRE Guidelines for CRIS Managers and Metadata Exchanges Between Databases
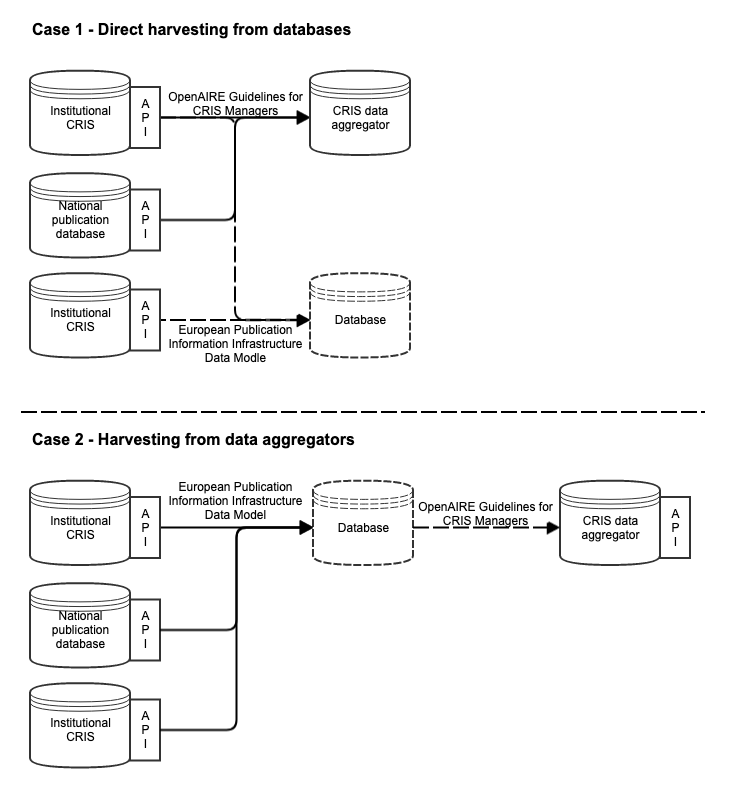
To demonstrate the metadata flows between ENRESSH Publication Database, institutional CRISs, national publication databases and CRIS data aggregators, two cases were drafted. In first case, the harvest to European Publication Information Infrastructure is made directly via OAI-PMH endpoints provided by data providers, that comply with the data model. This does not intervene with other harvests done to these exact same source systems as they can exist side by side. In second case, the CRIS data aggregators can in addition to harvesting directly from source systems, use the European Publication Information Infrastructure to further aggregate the publication metadata.
When the metadata exchange is done via OAI-PMH API endpoints, the publication metadata can flow to various aggregators and databases. Thus, there is no meaningful difference, if metadata to aggregating databases is collected straight from the source systems, as it can be harvested via European Publication Information Infrastructure as well.